
Talk:Power of a test
| This article is rated C-class on Wikipedia's content assessment scale. It is of interest to the following WikiProjects: | |||||||||||
| |||||||||||

|
This article links to one or more target anchors that no longer exist.
Please help fix the broken anchors. You can remove this template after fixing the problems. | Reporting errors |
Link[edit]
The article links to an article which purports to be about using statistical controls to improve power, but the page linked to is not about this, it is about process control, which is a completely different subject.
As for the misleading link, I added a Reliability (psychometric) page for the link to reliability. I don't know that you always have to use psychometrics to increase reliability, although maybe that's just a quibble. Jfitzg
Thank you for fixing the link, but I still think it's not quite right. This is only my opinion, but I think that a user clicking on 'reliability' does not expect to go to an article on reliability in psychometrics. What about in other branches of statistics? We should use the principle of least surprise, and make the link explicit, e.g. "by increasing the reliability of measures, as in the case of psychometric reliability". -- Heron
- Good idea. Jfitzg
On the meaning of power[edit]
The article says, "The power of the test is the probability that when the test concludes that there a statistically significant difference between test scores for men and women, that the difference found reflects a true difference between the populations of men and women." That seems backwards to me. Rephrasing, it says, "The power of the test is the probability that when the test rejects the null hypothesis, that the null hypothesis is false." Isn't that backwards?
I think the sentence should read, "The power of the test is the probability that when there is a true difference between the test scores of men and women, the test concludes that there a statistically significant difference between the populations of men and women." --Kent37 00:24, 12 October 2006 (UTC)
Power = probability of rejecting a valid null hypothesis??? Wrong! That is the exact opposite of the truth. Power is the probability of rejection, usually as a function of a parameter of interest, and one is interested in having a powerful test in order to be assured of rejection of a false null hypothesis. Michael Hardy 19:52 2 Jun 2003 (UTC)
Increasing the power of a test does not increase the probability of type I error if the increase in power results from an increase in sample size. I have deleted that statement. Michael Hardy 19:58 2 Jun 2003 (UTC)
- Thanks for the corrections. Valid was a slip, as the next paragraph shows. Bad place to make a slip, though. I was afraid I had left the impression that increasing power increases the chance of Type I error, and had already made a change to avoid leaving the impression, but apparently it wasn't good enough. Jfitzg
beta[edit]
It might be worth mentioning that some texts define beta = power, not 1 - power. See for example Bickel & Doksum 2nd edition page 217. Btyner 19:47, 7 November 2006 (UTC)
anyway a section can added for the stats newbie, using a more intuitive/conceptual approach? i found the posting difficult to follow because i didn't know what half the terms meant. 204.141.184.245 16:14, 20 July 2007 (UTC) N
Removed post-hoc power[edit]
I've removed the mention of post-hoc power calculations from the 2nd para as they are generally agreed to be a bad idea, certainly in the form that was stated (power for the sample size you used and the effect you estimated) when the power is a function of the p-value alone. For more details google "post-hoc power" or see this thread on the Medstats discussion list. --Qwfp (talk) 19:03, 23 January 2008 (UTC)
The missing full reference for John M. Hoenig and Dennis M. Heisey is in DOI:10.1198/000313001300339897 http://amstat.tandfonline.com/doi/abs/10.1198/000313001300339897 I don't know how to edit references — Preceding unsigned comment added by 96.127.225.218 (talk) 12:16, 30 March 2013 (UTC)
Null Hypothesis[edit]
Remember that greater power means higher likelihood of getting a statistically significant result, which could still be the null hypothesis.
Huh? A statistically significant result is a result that rejects the null hypothesis, right? 68.239.78.86 (talk) 04:38, 7 March 2009 (UTC)
The null hypothesis is that there is no effect. Power is the ability to detect an effect if it is there. You do not need power to detect the null hypothesis, because it is assumed a priori that the null is true, until a significant effect is found.
Sorry, no, the null does not mean that there is no effect (although most textbooks of non-statisticians about statistics make this claim). Compare Fisher's "The Design of Experiments" (ch.8) or Cox & Hinkley's "Theoretical Statistics". The null hypothesis is just the hypothesis to be tested (and therefore a proper null should be the research hypothesis, be it a nil or non-nil one; the common practise to have a research hypothesis of some effect, but to set a strawman null which is tested, does not provide evidence in favor of the research hypothesis but only against the null, unless all other alternatives have been ruled out), and the base requirement is that it is exact (because otherwise it wouldn't be possible to characterize a test distribution and a test wouldn't be possible). The reason why this error is repeated everywhere is that a nil-null assumption is exact (e.g. d=0). If, however, an exact non-nil null hypothesis is assumed (like H:Effect is d=0.6), it is perfectly possible to test it (using a proper distribution, though; in the case of a t-test, the proper test distribution is a non-central t distribution).Sciencecovskij (talk) 07:34, 14 October 2016 (UTC)
A "statistically significant result" is significant because either 1) a true effect was found, or 2) a type-I error occurred, where it looked like there was a true effect but actually the difference came about by chance.
I'll remove this statement. —Preceding unsigned comment added by 78.32.109.194 (talk) 23:42, 26 May 2009 (UTC)
Sectioning[edit]
I just added a provisional structure to the article by introducing some sections. I was surprised to find that an article on such an important statistical concept basically was one long piece of text. The matter at hand is certainly not a simple one and I feel its various aspects merit individual attention. The division into sections may make it slightly more easy to read, and perhaps some readers are interested in only certain sections. It's by no means perfect, and I'll be glad to see others improve it, renaming sections, subdividing (currently, the Background section is somewhat long and diverse, and the Intro a bit technical perhaps?). Cheers! Evlshout (talk) 05:37, 31 March 2009 (UTC)
Calculating statistical power[edit]
Power analysis can either be done before (a priori or prospective power analysis) or after (post hoc or retrospective power analysis) data is collected.
There is no information on the wiki about how to calculate the statistical power. Anyway, I can not find it elsewhere either, and had expected the wiki to state this, as such calculations are present in most other statistical wikis. —Preceding unsigned comment added by DBodor (talk • contribs) 17:09, 14 April 2009 (UTC)
What does "trade-off" mean?[edit]
The article says "most researchers assess the power of their tests using 0.80 as a standard for adequacy. This convention implies a four-to-one trade off between β-risk and α-risk". Does "trade-off" mean "ratio". How would this be calculated. Power is said to be a function, which is not, in general, a single number, so it depends on the size of the "effect". If thse researchers wish to calculate a difference or ratio of numbers, are they assuming a particular number for the "effect"?
Tashiro (talk) 14:31, 9 September 2011 (UTC)
Composite hypothesis[edit]
As the alternative mostly is composie, it is too simple to suggest the power is just one number. Nijdam (talk) 22:48, 18 October 2011 (UTC)
Title[edit]
As far as I know the title does not cover the subject. The power of a test isn't called statistical power. My suggestion: change the title to "Power (statistics)". Nijdam (talk) 22:01, 14 October 2011 (UTC)
Please stop removing links to free software[edit]
As odd as it may sound to those who love editing pages on topics they know nothing about, there are those of us who actually have to implement some of the methodologies presented on some of these wonderful pages. I make power and sample size calculations for real life work. Not everyday, but from time to time. I refer myself back to wikipedia to find links to all sorts of software on several methods pages. When I came back to this page to recall a link to a FREE resource I'd put to good use in the past had been removed, I was extremely disappointed. I literally waded through the mass of edits to find it. I hope the next person doesn't have to do the same. If you don't want links to for-pay software -- fine. But PLEASE leave the free ones, especially if they're open source for crying out loud. — Preceding unsigned comment added by TedPSS (talk • contribs) 05:14, 7 July 2016 (UTC)
- TedPSS - I agree with you that such links are important, but I think the issue for some editors is avoiding the External references section becoming a list that dwarfs the article as people add more and more links to software (such as detailed in WP:NOTLINK). Are there any lists of free and/or open-source software that can be linked in the external references? This may be a tidier solution. — Sasuke Sarutobi (talk) 07:46, 14 October 2016 (UTC)
- The UCSF Biostatistics department has a list of power and sample size programs and websites and allows one to view by cost if so wished. It was last updated in 2006, however. Qwfp (talk) 12:31, 14 October 2016 (UTC)
Isn't power specificity, not sensitivity?[edit]
The intro deems power to be the sensitivity, but notes that power is 1 - (the false negative rate) = the true negative rate. That sounds like **specificity** to me. — Preceding unsigned comment added by Zeng.chi (talk • contribs) 08:50, 10 August 2016 (UTC)
- No, 1 – (false negative rate) = (true positive rate), as per the article Sensitivity and specificity#Definitions. Power = 1 – (false negative rate) = = sensitivity. Loraof (talk) 21:28, 19 September 2017 (UTC)

Misleading jump in reasoning[edit]
"the probability that the test correctly rejects the null hypothesis (H0) when the alternative hypothesis (H1) is true"
Non sequitur. Rejection of null hypothesis doesn't imply that the alternative one is true. — Preceding unsigned comment added by Pn4vin (talk • contribs) 19:23, 26 March 2017 (UTC)
- It doesn't say that rejection of the null hypothesis implies the alternative one is true—it says the reverse of that: If the alternative one is true, it's correct to reject the null. Loraof (talk) 20:24, 19 September 2017 (UTC)
Link to Recall (as in Precision and Recall) ?[edit]
Am I just delusional or is the definition given here for statistical power exactly the formula used to define Recall in Precision_and_recall, i.e. true positives divided by the sum of true positives and false negatives (cf. Type_I_and_type_II_errors#Table_of_error_types for clarification)? If so, why is there no link to Precision_and_recall here and no link to this article in Precision_and_recall? Catskineater (talk) 01:24, 5 December 2017 (UTC)
Misleading variables in example ?[edit]
The example uses for the same variable. This is confusing. — Preceding unsigned comment added by Tedtoal (talk • contribs) 22:02, 2 March 2020 (UTC)

Effect of α on statistical power?[edit]
The article says that increasing α would increase statistical power, because you set a weaker threshold to reject the null, and therefore you'll end up with statistically significant results more often. I don't understand how this connects with statistical power though. If we talk about the conditional probability of getting a stat significant result given that the null is true, then increasing α increases the likelihood of a positive (and inaccurate) result. On the other hand, if we look at the conditional probability that a result is accurate given that it is stat significant, then decreasing α would increase this probability. I don't see how, however, α would have impacts on statistical power, which is a conditional probability given that the null is false, i.e., stat power is sort of like sensitivity, or how often will I get a stat significant result when there is an actual effect present. α is conditional on the effect not being there, so I don't quite understand why changes to the conditional probability α given that the null is true affect the conditional probability of stat power given that the null is false. It's like it's two different realms, α is related to the specificity of the experiment and β is related to its sensitivity, and these two are independent events so I don't see how they affect one another.
In other words, sensitivity (1-β or stat power) and 1-sensitivity (type II error) always add up to 1. Specificity (1-α) and non-specificity (type I error) also always add up to 1. But the sum of sensitivity and specificity are not constrained by a similar relationship, hence α and β are also not so related as the text suggests Themidget17 (talk) 20:55, 5 May 2021 (UTC)
ok so I was wrong and I found the following graph that makes very clear the relationship between alpha and beta. The gist of it is that while alpha and beta can be expressed as percentages, they actually represents a cutoff value for the parameter being studied, and that cutoff value is, naturally, the same whether the hypothesis being tested is true or not. See the image here Themidget17 (talk) 00:41, 6 May 2021 (UTC)
is the image wrong?[edit]
https://en.wikipedia.org/wiki/File:Statistical_test,_significance_level,_power.png
{kind=link}
looking at other examples on the internet, the type 1 error rate is in a different spot for two-sample tests
https://liwaiwai.com/wp-content/uploads/2019/10/stat-type1-type2-error-1.png
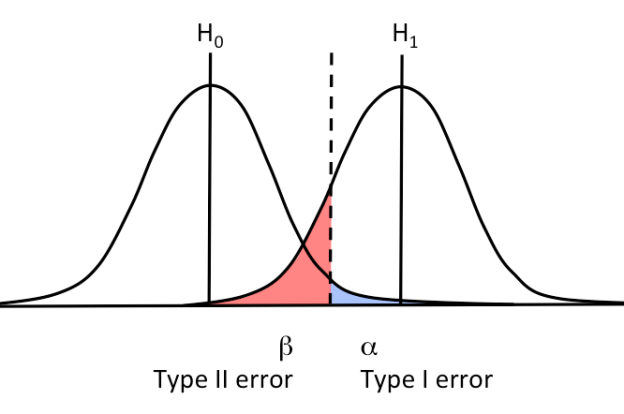{kind=link}
{kind=link}
https://miro.medium.com/v2/resize:fit:1400/1*qXmpMtzvQM1z8ov1DUwbew.png
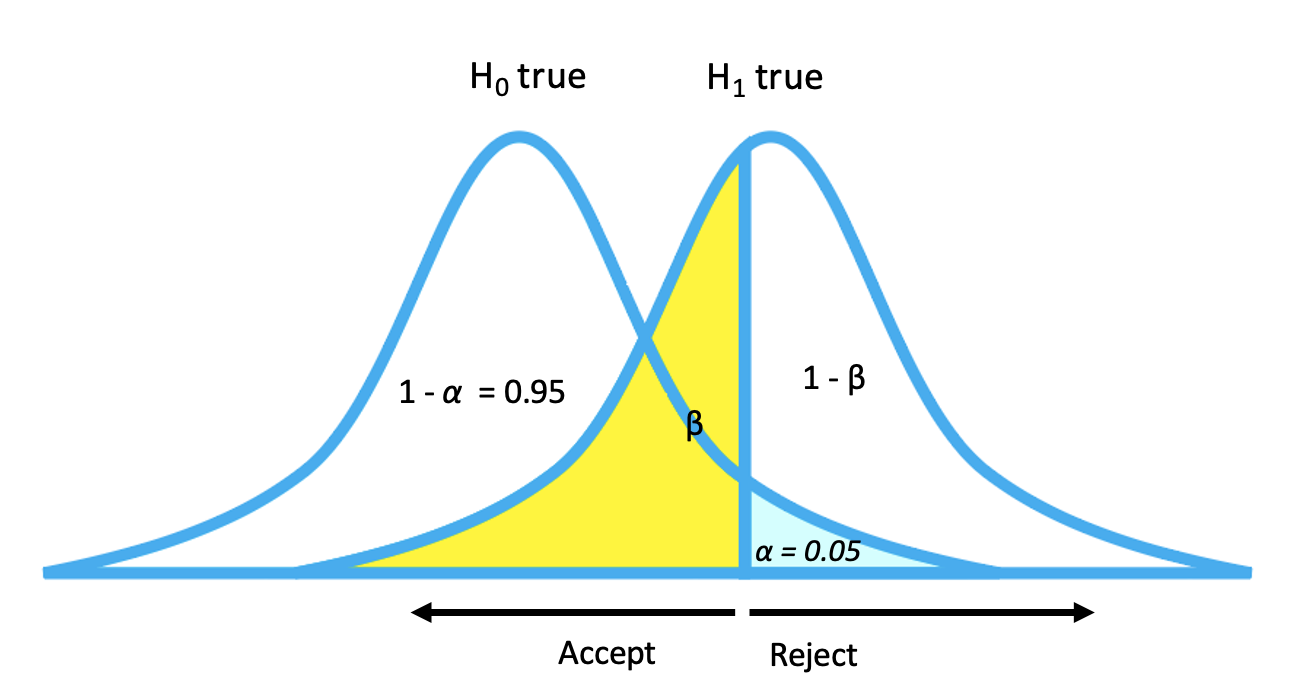{kind=link}
https://www.mdpi.com/make/make-01-00054/article_deploy/html/images/make-01-00054-g005.png 71.40.21.124 (talk) 02:29, 12 February 2024 (UTC)
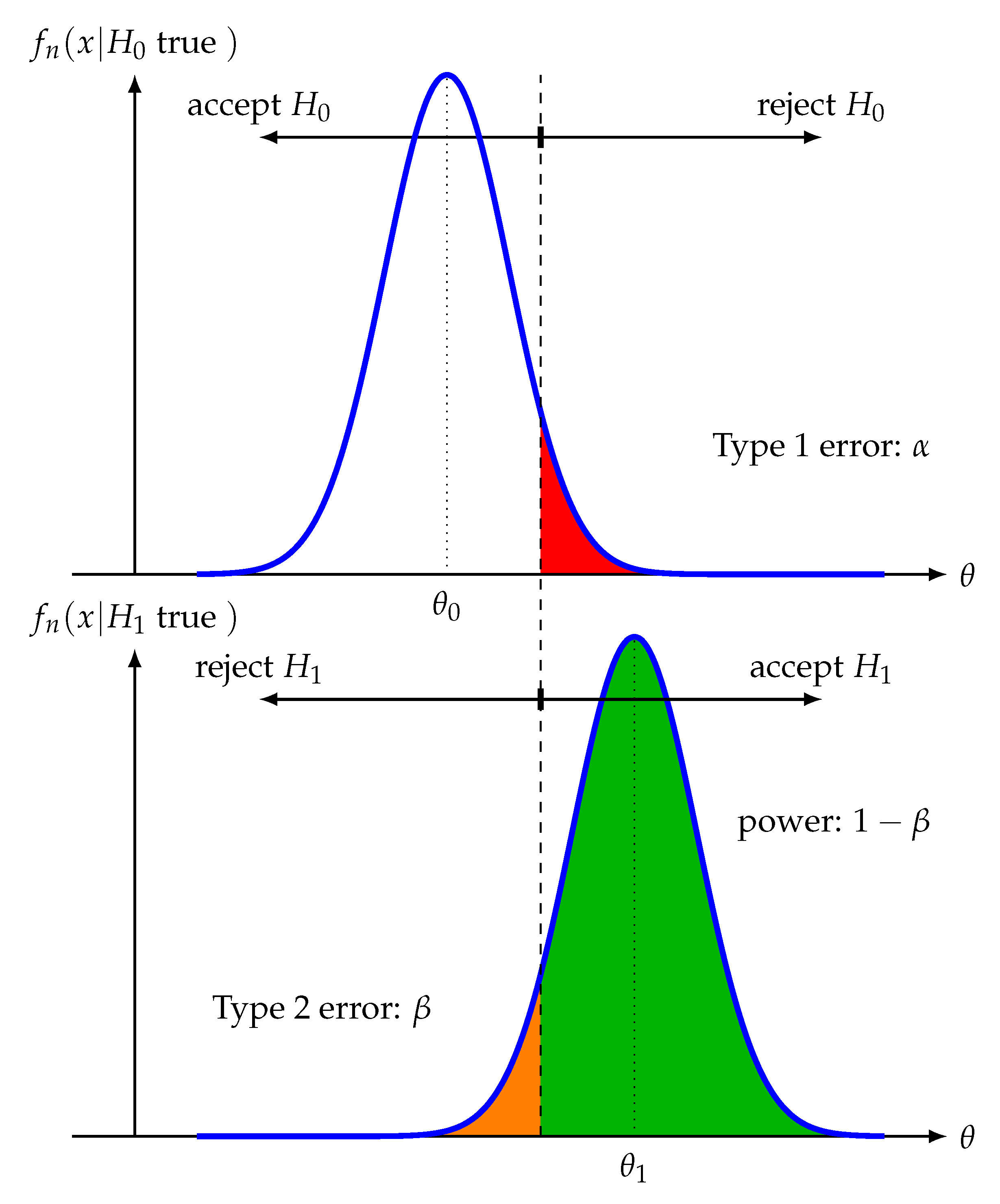{kind=link}